Blog The performance improvements in Ruby 3.3 with YJIT
Ruby 3.1.2 vs 3.3.5+YJIT in production
In the previous article I discussed about my upgrade process from Ruby 3.1 to ruby 3.3, discovered a potential regression in a specific scenario, and ended up with synthetic benchmark results looking pretty great:
 |
 |
|---|
Basically much higher performance thanks to YJIT, with an even lower memory usage then before, it's looking good + good.
After running it in production for the last 2 days now let's see how the numbers compares with the benchmark made previously:
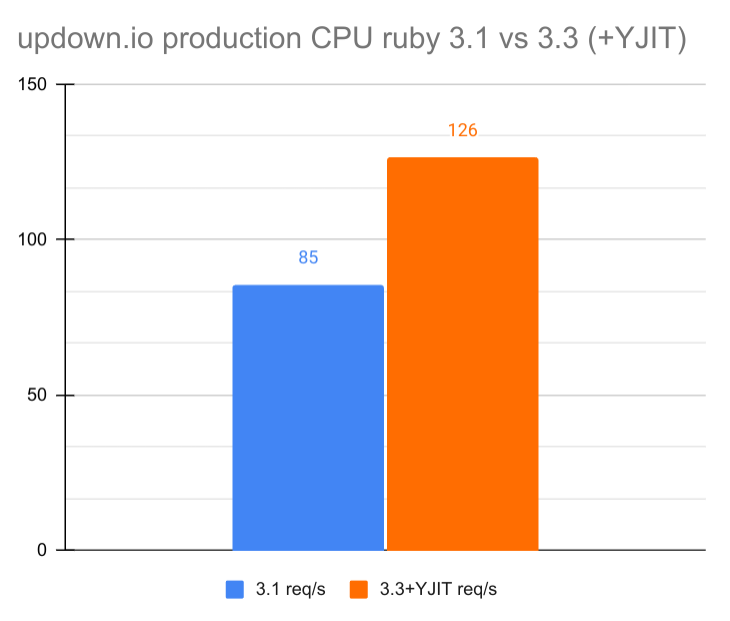 |
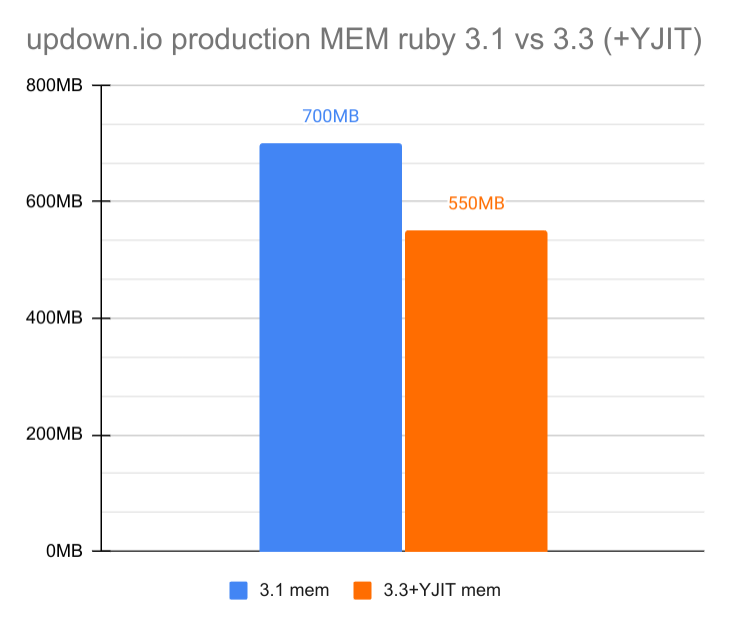 |
|---|
Note: in production there's only a fixed number of requests/s so it's the CPU usage which decreased instead of the req/s increasing. But for this chart in order to make it easier to compare with the benchmark, I normalized the fixed req/s by the CPU usage to get an estimate "maximum req/s" for one server.
🎉 This is great, I'm getting a 32% lower CPU usage, which means that on the same CPU I can execute around 48% more requests/second (yes these numbers are not supposed to be same, because a 50% decrease in CPU usage would mean you can run twice as many requests so +100% req/s) This is equivalent and even slightly better than the benchmark, most likely because the servers I'm running it on are shared CPU VPS, so they are overselling CPU cores (and which are actually threads not cores). So basically the more you use them the slower each CPU "core" gets.
🎉 Also as you can see I'm getting a 21% decrease in memory usage !! and that's with YJIT enabled in 3.3.5 and no YJIT in 3.1.2.
I didn't test 3.3.5 wihout YJIT in production as I didn't see any reason to, and also I don't have numbers of 3.1.2 with YJIT (I tested it quickly a few years ago).
Obviously your mileage may vary, I think I have a use-case here which is very well suited for YJIT optimisation because:
- It's a small codebase with the same few Sidekiq worker running over and over again (~50 times per second per server), so by compiling few ruby methods which rarely change, YJIT can make a good impact.
- The CPU time is spent almost exclusively in Ruby code (mostly the Mongoid ORM when communicating with MongoDB), because the rest is libcurl performing http(s) requests which is IO bound. The only CPU-intensive part which is not optimizable by YJIT is the TLS handshake implemented in C by OpenSSL, but it's a small part.
- I'm not improving much the total time of the worker here (blue) because it's more than 50% IO wait time, but it's not important in my case (and for background jobs in general) because I can run them concurrently and the user is not waiting for the response. So what's important is how much CPU each job needs (green):
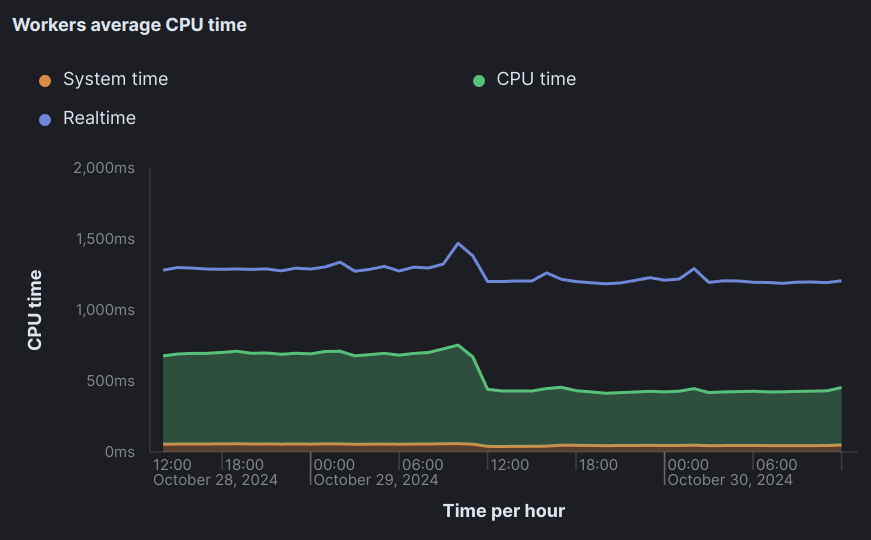
It's a different story on the web server part, I didn't even look at the numbers because it's a very small load on updown and with most of the time spent waiting on database requests, the difference wouldn't be very visible. On a more high-traffic and ruby-heavy web application though, the impact should be visible.
Ruby 3.3.5+YJIT with or without jemalloc ?
Another thing I noticed during my benchmark of 3.3.5 is that using jemalloc or not (on Linux) had a very small impact, the memory usage was almost the same. So I though maybe I don't need to use jemalloc anymore and I tried deploying one server with 3.3.5+YJIT but without jemalloc in order to compare the memory usage in a real world scenario:
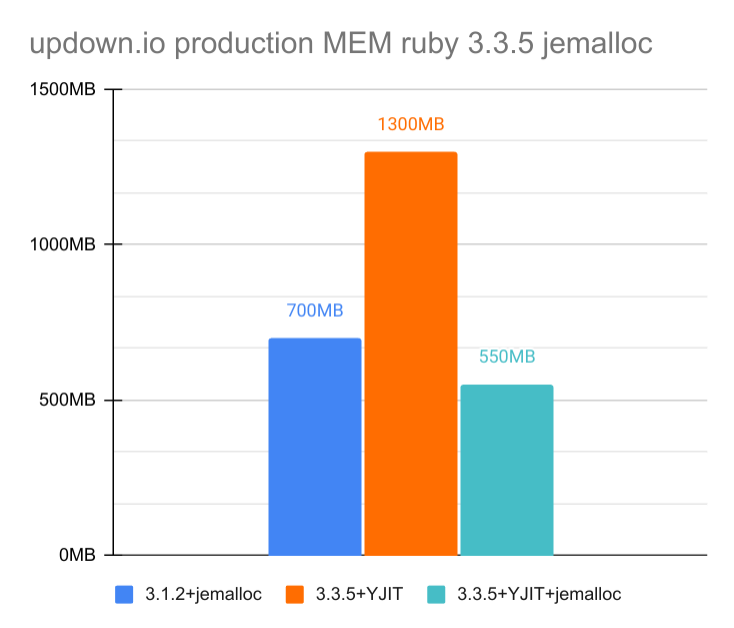 |
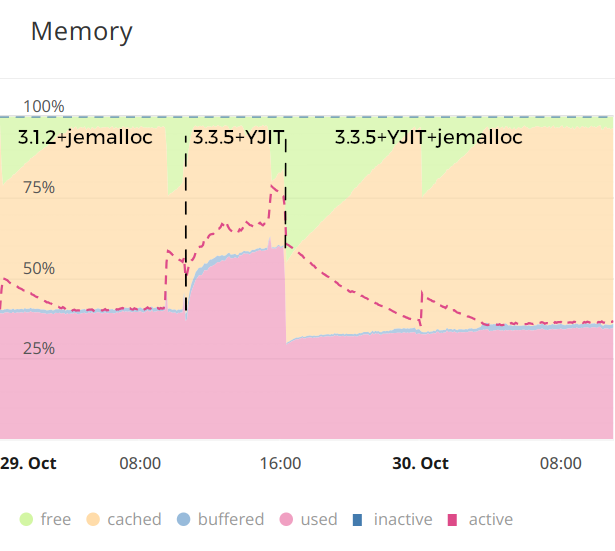 |
|---|
As you can see, despite the good numbers I got during benchmarking, in production it's a whole different story. I believe this is because in production the worker allocates much more memory to instantiate bigger Mongoid models and HTTP body of (wildly) different sizes, whereas in local benchmark the test data is much more limited and similar in size. This must create a lot of fragmentation or something like that, and jemalloc seems much better in this scenario. The difference (more than 50%) is even slightly greater than in my 2017 testing with ruby 2.3.0.
So the answer is yes, jemalloc is still extremely useful to limit ruby memory usage in 3.3.5 (at least on Linux, Ubuntu Server 24.04.1 LTS in my instance). And it's a free upgrade, all you have to do on most Linux is install libjemalloc and then compile ruby with the option.
So how do I compile Ruby 3.3.5 with YJIT and jemalloc ?
In my case I'm using rbenv to install ruby and this is what I need to do in order to compile ruby with both YJIT support and jemalloc on Ubuntu Server 24.04.1 LTS:
Install the dependencies:
> sudo apt install libjemalloc-dev rustc
And (re)install ruby with jemalloc and YJIT enabled:
> RUBY_CONFIGURE_OPTS="--with-jemalloc --enable-yjit" rbenv install 3.3.5
Note: --enable-yjit is not strictly necessary. As long as rustc is available it'll compile ruby with YJIT support. But the thing is if you don't have rustc installed, it'll also compile fine (without YJIT support) and you won't notice it until you actually need to use it. Using --enable-yjit makes sure the installation step fails early if the dependency (rustc) is missing.
👨💻 Protip: I also use --disable-install-rdoc to speed up the install as I don't need rdoc.
To check if ruby is compiled with jemalloc or not (watch for the presence of -ljemalloc):
> ruby -r rbconfig -e "puts RbConfig::CONFIG['MAINLIBS']"
-lz -lrt -lrt -ljemalloc -ldl -lcrypt -lm -lpthread
To check if YJIT support is enabled:
> ruby --yjit -ve 'p RubyVM::YJIT.enabled?'
ruby 3.3.5 (2024-09-03 revision ef084cc8f4) +YJIT [x86_64-linux]
true

Comments
Sign in to comment