Blog Weird results comparing ruby 3.1, 3.2 & 3.3 with jemalloc and YJIT
updown.io has been running on ruby 3.1 since... git log -p .ruby-version... August 2022 so for slighly over 2 years now. More specifically ruby 3.1.2 with jemalloc for better performance.
Note: I am not using YJIT in production yet, as my benchmark in 3.1.2 for updown.io daemon code showed a mere 5-10% CPU time performance increase, but with more than 30% memory increase. And after a few days of runtime the CPU time improvement would degrade (maybe due to the higher memory usage), down to a similar performance level without YJIT.
I left 3.2 on the table to save some time and choose to go directly to ✨ 3.3, once it'll be stable enough (so not 3.3.0). Now that 3.3.5 is released I decided to give it a try, starting first by running the automated test suite of course ! I only got one minor error to fix 🎉 the File.exists? method alias has removed, it's just File.exist? now.
Next comes the benchmarking, I have my own benchmark suite which is designed to be as close as possible to the real updown daemons work load: so it's running multiple sidekiq workers and making them execute http/https/tcp/tcps/icmp checks as quickly as possible (agains local stub endpoint to avoid any network bottleneck) and writting the results in MongoDB as the normal daemon would. This benchmark has multiple purpose:
- Testing hardware performance and virtualisation overhead to compare servers, with real-world numbers of updown performance (in requests/seconds).
- Testing changes to the codebase to make sure I don't introduce performance regressions, or to measure the impact of optimisations I write.
- Testing changes to the environement like the Ruby version, openssl version, the usage of YJIT or jemalloc. This is what I'm doing here.
After reading a lot of good things about performance improvements in ruby 3.2 and 3.3 (especially YJIT), I was excited to finally test it, without expecting too much of course but every bit of extra performance that we can have for free is awesome.
1. Testing 3.3.5
Ok let's install 3.3.5 and start testing (with jemalloc as usual):
$ RUBY_CONFIGURE_OPTS=--with-jemalloc rbenv install 3.3.5
👨💻 Protip: I also use CONFIGUREOPTS="--disable-install-rdoc" to speed up the install as I don't need rdoc.
I'll take only one performance number (using 4 workers on my Intel Core I5 9600k) to simplify the comparison, even though I do more testing behind the scene to confirm trends.
| Ruby version | Req/s | Comment |
|---|---|---|
| 3.1.2 + jemalloc (production) | 300 | |
| 3.1.2 + jemalloc + YJIT | 321 | 7% faster with YJIT |
| 3.3.5 + jemalloc | 200 | 🐢⚠️ |
| 3.3.5 + jemalloc + YJIT | 235 | 17% faster with YJIT |
Wait, what? Can 3.3.5 really be 33% slower than 3.1.2 for my application ??
I must be missing something here, on the other hand it's a big version jump so let's start reducing the difference and have a look at 3.2 first. At this point I'm thinking it's either:
- A performance regression in 3.2 or 3.3, which is maybe specific to my use-case if it wasn't noticed.
- An issue with jemalloc and 3.3 (as it's the only thing "out of the ordinary" I am doing)
- An unrelated quirk that will be super hard to find like some of the code/library I use which uses a different path depending on the ruby version or the persence of a method which is gone, etc... let's hope it's not that 🙃
2. 🤯 WTF, OK testing 3.2.5
I'll also test it with and without jemalloc while I'm at it, just to make sure:
| Ruby version | Req/s | Memory | Comment |
|---|---|---|---|
| 3.1.2 + jemalloc (baseline) | 300 | 324 MB | |
| 3.1.2 + jemalloc + YJIT | 321 | 7% faster with YJIT | |
| 3.2.5 + jemalloc | 308 | 322 MB | ✅ |
| 3.2.5 + jemalloc + YJIT | 348 | 361 MB | ↗️ 13% faster with YJIT |
| 3.2.5 | 301 | 336 MB | ✅ |
| 3.2.5 + YJIT | 355 | 381 MB | ↗️ 18% faster with YJIT |
So everything looks perfectly as expected here, the performance of 3.2.5 is slightly higher and the YJIT performance bump has increase since 3.1 which is very nice 👏. Also jemalloc still brings a small memory usage improvement and a very small CPU time improvement (though not as good with YJIT, depending on tests I made it was sometimes better and sometimes worse).
3. 🧐 Mm ok back to 3.3 then
Let's try without jemalloc and with some others 3.3 release maybe:
| Ruby version | Req/s | Memory | Comment |
|---|---|---|---|
| 3.1.2 + jemalloc (baseline) | 300 | 324 MB | |
| 3.1.2 + jemalloc + YJIT | 321 | 600 MB | 7% faster with YJIT |
| 3.3.0 | 194 | 243 MB | 🐢⚠️ |
| 3.3.0 + YJIT | 228 | 263 MB | 🐢⚠️ |
| 3.3.2 + jemalloc | 189 | 223 MB | 🐢⚠️ |
| 3.3.2 + jemalloc + YJIT | 224 | 239 MB | 🐢⚠️ |
| 3.3.5 | 200 | 220 MB | 🐢⚠️ |
| 3.3.5 + YJIT | 235 | 240 MB | 🐢⚠️ |
Ok so with or without jemalloc, we have similar results across the whole 3.3 line. But now that I added the memory usage you may notice something:
- How big the increase was in 3.1 with YJIT
- How small the memory footprint is in 3.3, compared with 3.1 and 3.2
- The jemalloc seems to have less impact now (which is not true actually, depending on the real conditions)
So now I'm starting to suspect some memory optimisations in 3.3 which could have been made at the expense of CPU performance, and maybe some tunable parameters (e.g. Garbage Collector) that changed default ?
4. 🧹 Let's compare GC settings ?
I had a quick look at the default values for GC tuning options and the GC.stat output in both versions to compare but nothing looked really different. I also checked if GC compaction was maybe enabled by default now but it's still not the case.
5. 🕵️♂️ Time for... the Flamegraph !
Ok let's go down the rabbit hole. So next step I ran my favorite sampling profiler rbspy on the worker process in 3.1 and 3.3 in order to see better where is the CPU time spend and why:
$ sudo ~/bin/rbspy record -d 240 -o flamegraph -f ruby31.svg -s --pid 141709
$ sudo ~/bin/rbspy record -d 240 -o flamegraph -f ruby33.svg -s --pid 155612
Now we can compare the graphs:
| Ruby | Flamegraph |
|---|---|
| 3.1 | 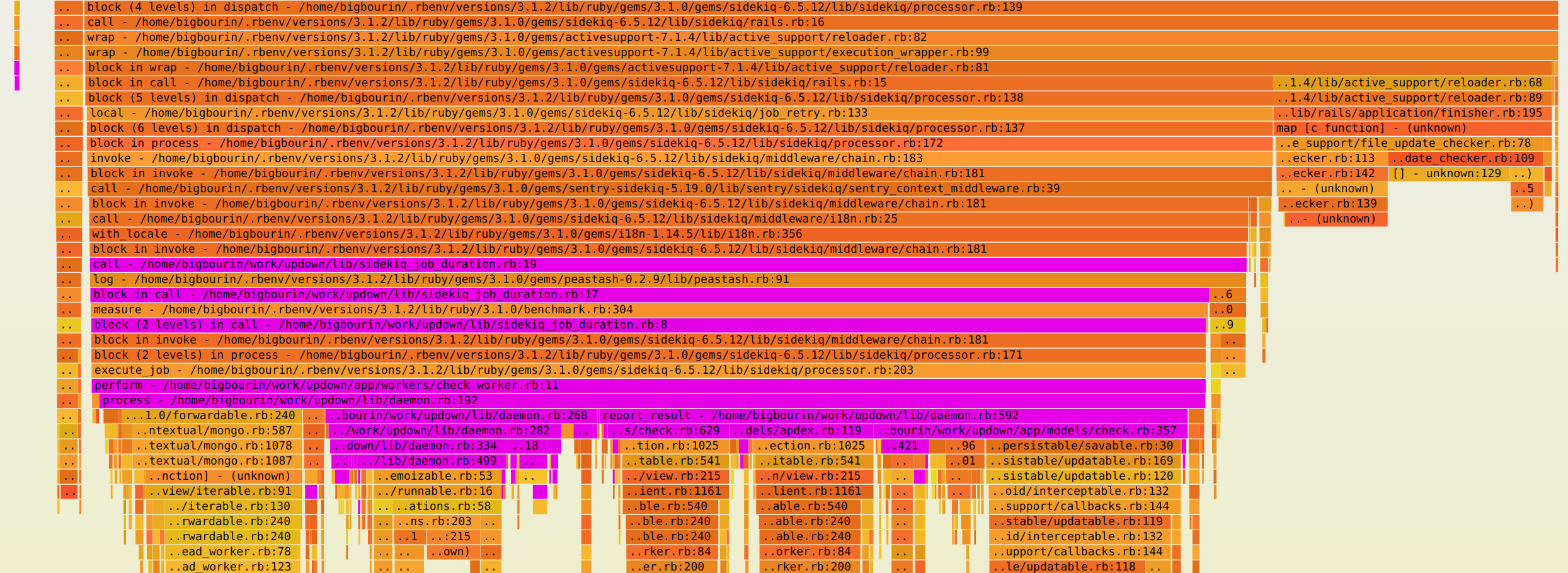 |
| 3.3 | 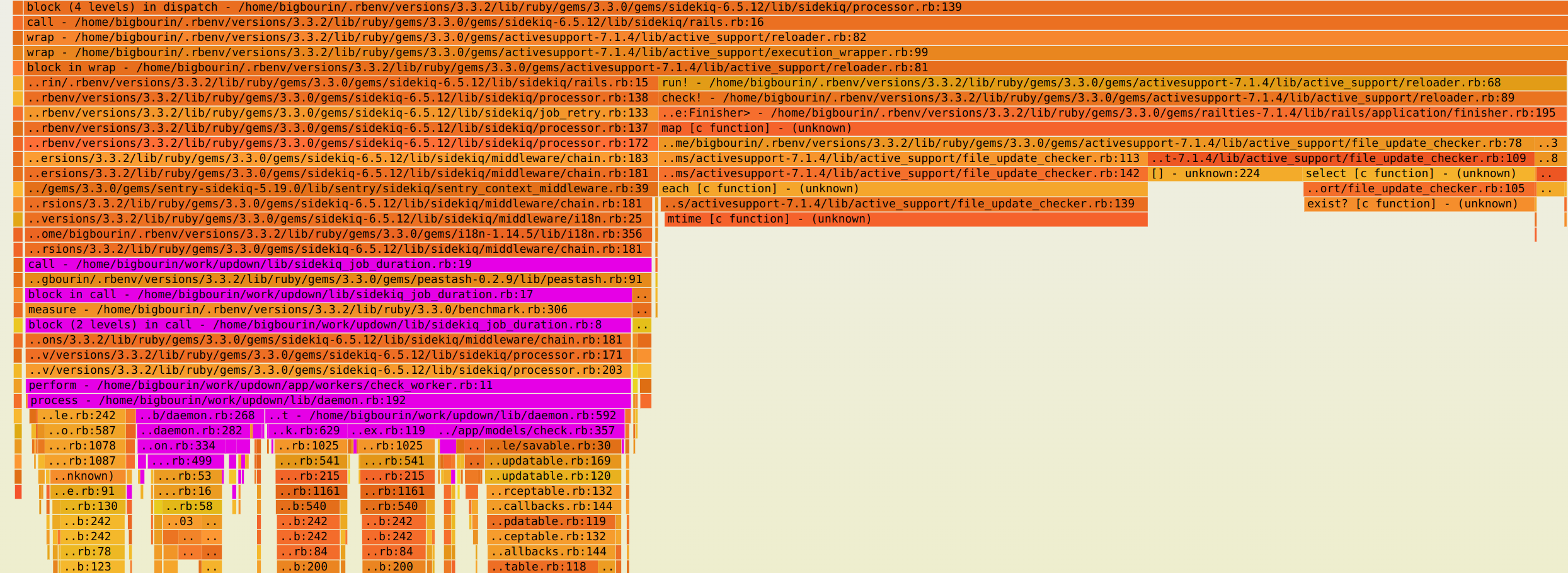 |
Aha ! There's definitely something huge visible here. What I highlighed in purple here is basically the meaningful work performed by the worker. And the remaining part on the right side (which is taking much more time since 3.3) is ActiveSupport::Reloader.
This is the Rails module responsible with detecting when source file are changed to automatically reload them. Definitely not necessary here for a benchmark, I could run it in staging/production env or disable file reaload. But that would mean ignoring a big regression which is taking 3 times more CPU !! We need to understand why, I can't look away now.
6. 🐇 Down the rabbit hole
Having a quick look at the file_updater_checker.rb, I see 3 options:
- The underlying code is slower un ruby 3.3 → this is unlikely IMO because I can see it calling the
mtimeC function for example, for 3 time as long, and this function would take the same time between several ruby version (runing on the exact same machine/files/SSD of course) - The underlying code is called much more often, meaning the Rails reloader is attempting to reload the code 3 times as often as before.
- Or the reloader is actually tracking 3 times as many files (maybe due to a difference in globing implementation or filtering). There's several loops iterating on each file/path inside the file_update_checker.
I can easily test for 2 and 3 with a very scientific instrumentation:
$ bundle open activesupport
def updated?
current_watched = watched
STDERR.puts "ActiveSupport::FileUpdateChecker#updated? called #{$yolo=($yolo||0)+1} times with #{current_watched.size} files"
if @last_watched.size != current_watched.size
# ...
end
Aaaand nop, at the end of my benchmark I see about 50k calls and about 142 files in both cases (ruby 3.1 and 3.3)...
Just to be sure, I added two extra counters at the exact place were we call File.mtime (the C function) and File.exist? (another C fuction). These two functions are the bottom of the two biggest flames under the right section (the ActiveSupport::Reloader). We can't see inside because the functions called from C do not appear in the Ruby backtrace monitored by rbspy.
Still nop:
| Ruby | File.mtime | File.exist? |
|---|---|---|
| 3.1.2 | 3047858 | 1266973 |
| 3.3.2 | 3063878 | 1272286 |
So if I have exactly the same amount of calls, is it really possible that File.mtime got 3 times slower ? Let's benchmark it 10M times:
require 'benchmark'
puts RUBY_VERSION
puts Benchmark.measure { 10_000_000.times { File.mtime(__FILE__) } }
$ ruby script/benchmark/mtime.rb
3.1.2
5.889876 7.440399 13.330275 ( 13.357812)
$ ruby script/benchmark/mtime.rb
3.3.5
6.705540 7.507902 14.213442 ( 14.214228)
Nop, we can see a small increase in user CPU time indeed (about 20%), but nothing that would explain the 300% increase we saw in that flamegraph. It's the same thing with File.exist? by the way.
I even tried benchmarking the Rails Reloader entirely in a Rails console (so that I'm using the same set of ~140 paths):
RUBY_VERSION
# "3.3.5"
puts Benchmark.measure { 10_000.times { Rails.application.reloader.check! } }
# 7.742250 8.177783 15.920033 ( 15.945087)
RUBY_VERSION
# "3.1.2"
puts Benchmark.measure { 10_000.times { Rails.application.reloader.check! } }
# 7.209845 8.098117 15.307962 ( 15.309301)
Nop.
So what's left ? I need to investigate what difference (between this reloader benchmark and my complete benchmark) is causing such a huge performance gap for the same code.
I'm using threads, 80 threads per sidekiq worker to be precise, because my workload is mostly I/O (network requests). So maybe the difference is in the fact all of this (my workers + the rails reloader) are running massively concurrently in the sidekiq worker ?
I thought about the new N:M thread scheduler introduced in 3.3, but this is not enabled for the main ractor by default. I compared my number of running threads with 3.1 and 3.3 and it's similar. Still I tried to "disable" it with RUBY_MAX_CPU=100 (I'm using less threads than that so it would not be limiting) and it didn't change anything, as expected.
7. Making progress
Ok so let's start again from the benchmark and try to reduce it to the smallest possible code sample which can exibit this difference. I'm not going to show the code samples for all steps for brievity.
- First I determined that the time difference seems to be in the syscalls from
ActiveSupport::Reloader, so it looks like my own code has nothing to do with it. Then let's try with a totally empty Sidekiq worker instead of my complex monitoring daemon → ✅ it works (meaning I still reproduce the time difference and it's even greater now) - Then let's remove Sidekiq and try using instead a similar
Concurrent::ThreadPoolExecutorfrom the awesome concurrent-ruby. Inside the job I just usedRails.application.reloader.check!to simulate the Sidekiq wrapper calling this → ✅ it works. When benchmarking this code standalone in a single thread I didn't see any difference (see previous section), but now that I'm using a thread pool it does show a big difference with ruby 3.3. This is starting to confirm my theory around multi-threading and scheduling - Next step: as we saw it was mostly the syscalls, let's reduce the example again to just
File.mtime(__FILE__)→ ✅ it works. This is great news, I now have a very small reproducible ruby example which doesn't even involve Rails. This is what I have now:
#!/usr/bin/env ruby
GC.disable # just to make sure it doesn't skew results
THREADS = (ARGV.first || 10).to_i # choose thread count from CLI
N = 10_000_000 # to make the test longer or shorter
puts "Ruby #{RUBY_VERSION} / YJIT: #{RubyVM::YJIT.enabled?} / #{THREADS} Threads"
Array.new(THREADS).map do
Thread.new do
(N/THREADS).times { File.mtime(__FILE__) }
end
end.each(&:join)
puts "#{N} calls completed"
Now lets compare ruby 3.1.2 and 3.3.5 with this micro benchmark with different thread numbers. I'm using time to measure real time + user and system time, and I ran each command a couple times to get an average:
> time ./script/benchmark/ruby33.rb 1
> time ./script/benchmark/ruby33.rb 2
> time ./script/benchmark/ruby33.rb 4
> time ./script/benchmark/ruby33.rb 8
> time ./script/benchmark/ruby33.rb 16
...
| Ruby | 3.1.2 | 3.3.5 | comment |
|---|---|---|---|
| 1 thread | 13.7s (4s user / 9.6s system) | 14.2s (4.4s user / 9.7s system) | ✅ just a bit slower as we already saw |
| 2 threads | 9.7s (5.2s user / 11.9s system) | 33.4s (9.2s user / 34.8s system) | 💥 WOW THERE IT IS, no need to go very far. |
| 4 threads | 23.2s (10.6 user / 40.6s system) | 37.0s (10.4s user / 35.2s system) | 🧐 Wait why is it faster and then... |
| 8 threads | 21.8s (9.9 user / 37s system) | 39.7s (12.1s user / 36.4s system) | |
| 16 threads | 23.1s (11.4 user / 37.5s system) | 41.5s (13s user / 37.5s system) | It's starting to stabilize. |
| 32 threads | 22.1s (11.4 user / 35.3s system) | 43.2s (14.4s user / 37.8s system) | |
| 64 threads | 21.5s (11.3 user / 33.8s system) | 43.6s (13.8s user / 38.7s system) | |
| 128 threads | 21.7s (11.4 user / 34.2s system) | 43.7s (14.4s user / 38.5s system) |
These numbers are a bit weird (I didn't expect them to do this for 3.1.2 but anyway this is not a maintained version so not need to dig into it more I suppose). But they clearly show a regression in 3.3. Which is related to threading + syscalls apparently.
Is it the same with any syscall or C function though ? I tried with the very similar File.exists? call and saw the same results. I also tried with the simpler sleep which is another C function but didn't saw any difference there, it's much slower though even with the lowest possible delay so maybe this is slow enough to completely hide the speed difference.
This made me think about the new N:M thread scheduler introduced in 3.3 again, because even though it's not enabled by default for the main Ractor, it may have changed part of the code to introduce this change. Now maybe it's less efficient with the feature present but disabled but what if I actually try it on ? (with the RUBY_MN_THREADS=1 option). It does sound like a good candidate to test at least:
> time RUBY_MN_THREADS=1 ./script/benchmark/ruby33.rb 1
> time RUBY_MN_THREADS=1 ./script/benchmark/ruby33.rb 2
> time RUBY_MN_THREADS=1 ./script/benchmark/ruby33.rb 4
...
The results are surprising:
| Ruby | 3.1.2 | 3.3.5 | 3.3.5 with RUBY_MN_THREADS=1 |
|---|---|---|---|
| 1 thread | 13.7s | 14.2s | 14.5s ✅ OK similar |
| 2 threads | 9.7s | 33.4s | 12.3s 🎉 Aah much better ! |
| 4 threads | 23.2s | 37.0s | 40.5s 🧐 Wait that's not really better here |
| 8 threads | 21.8s | 39.7s | 37.9s |
| 16 threads | 23.1s | 41.5s | 36.3s |
| 32 threads | 22.1s | 43.2s | 40.9s |
| 64 threads | 21.5s | 43.6s | 36.2s |
| 128 threads | 21.7s | 43.7s | 39.3s |
Especially as this feature is limited to 8 "real" threads (and I'm on a 8 core / 16 threads CPU), so I wouldn't expect the performance to improve drastically for 2 threads but not 4 or 8.
All this was run on Ubuntu 24.04.1 LTS.
IMO this indicates again that the "regression" is around threading/scheduling & syscalls, but I'm not sure what else to test at this point. I think I'm gonna write this up to the Ruby team (edit: https://bugs.ruby-lang.org/issues/20816) and see what they think about it. If you have suggestions let me know, and I'll update the blog posts with future details.
8. Testing without the reloader
✏️ Edit: 2024-10-26
In the meantime, as this problem is amplified by the use of ActiveRecord::Reloader (which is not relevant to production), I tried running this benchmark again without the reloader in order to evaluate the actual performance impact/gain I may see in real production. Because if that part is good enough, I don't even need to wait for the result of this regression analysis before deploying 3.3 to production.
There's a lot of numbers here and I heard you like charts so let's show them nicer this time:
 |
 |
|---|
- We can see the raw performance is slightly lower with 3.3.5 compared with 3.1.2 without JIT (this may be related to the regression discussed before). BUT on the other hand we can see the awesome work done by the ruby team on YJIT. It's way faster than before and I'm totally ok to accept a small performance regression on bare ruby if I can get up to 30% more performance out of YJIT (more numbers below) !! 🎉
- And now looking at memory usage, as briefly discussed earlier, I was also amazed by the fact that 3.3 with YJIT actually has a lower memory usage than 3.1 wtihout YJIT 😍 (in my use-case at least). This is a tremendous improvement from YJIT in 3.1 as you can see.
Here are the raw numbers:
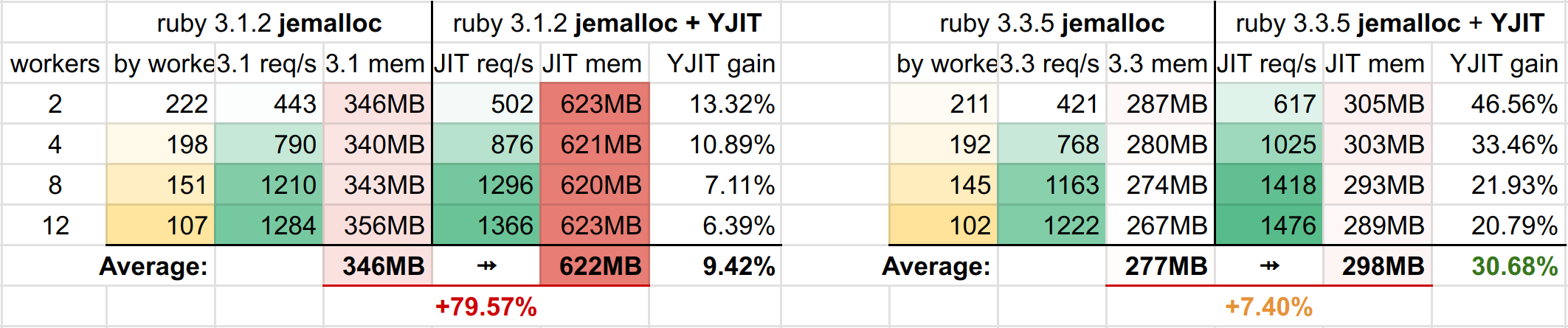
So despite the small performance regression between 3.1 and 3.3, we're still going from +9% average YJIT gain to +30% !!! And all of that, with a lower memory usage 🤯
Well done, ruby team, bravo 👏
I think it's time to try this out in production now 🚀 to be continued...

Comments
Sign in to comment