Documentation How pulse/cron monitoring works?
Pulse monitoring (also called "cron" monitoring) is a special type of monitoring where your service calls updown.io regularly, instead of the opposite. The goal is usually to make sure a periodic task is executing when it should and completing successfully. It can also be used as a way to monitor systems which are not exposed to the internet publicly.
As long as your service is pinging updown.io regularly (we'll call that a "pulse") it'll be considered UP. If updown did not receive any pulse after the configured amount of time, the service will be considered DOWN and you'll get alerted.
How to create a pulse check
To create a Pulse check on updown, simply select the "pulse" type in the select on the left:
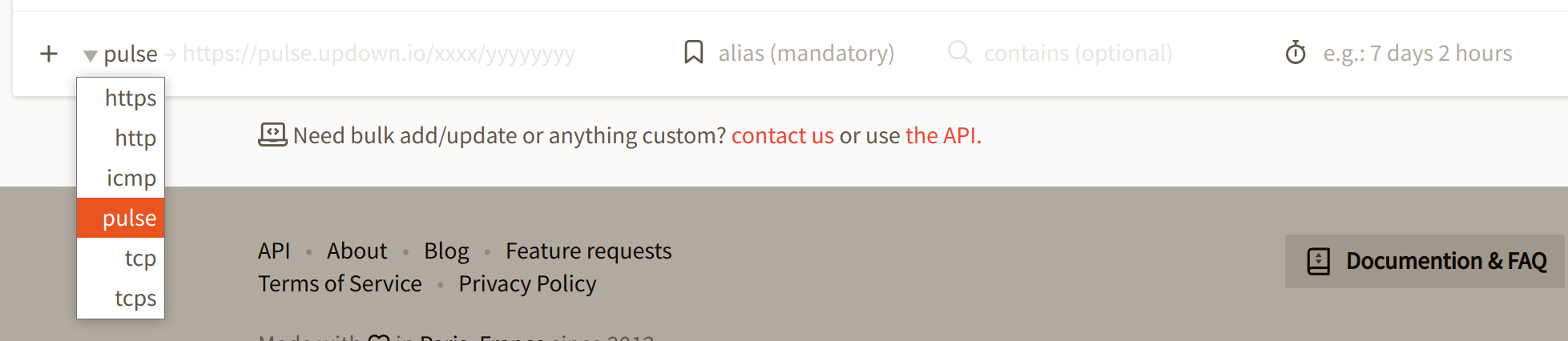
The form will change slightly and you'll need to specify:
1. An alias which will be the name of the check as there's no external URL here
2. A time interval before notification. It can be any duration between 15 seconds and 1 month + a few days. If updown did not receive any pulse after this duration, the check is marked as DOWN. Natural English format is accepted here thanks to chronic_duration.
For example: if you want to monitor a daily backup cron task, you could use "Daily backup" as an alias and "26 hours" as the period. You should often specify a period which is slightly longer than your task planned interval. This is in case the backup finishes at 03:32 one day and then 03:57 the next day for example, you probably don't want to be alerted right at 03:32 but instead give it a bit of margin. Also if your server crontab/scheduler is using a timezone with daylight savings, your cron task interval might be 1h longer once per year, so if you don't want an alert when this happens you better pick at least 1h more than the configured interval.
Special case: Monthly tasks
If you have a monthly task (e.g. every 1st day of the month, every 14th or even every last day of the month), you can use for example "1 month 2 hours" in the duration selector (2h being the grace period of your choosing to account for task duration).
After each pulse, updown will compute the alert time to be next month the same day instead of using a fixed number of day. This way you don't have to worry about months having 31 or 30 days (heck some even have fewer than that!).
Also if your task is on the last day of the month, updown will detect that and also expect it on the last day of next month (for example after a pulse on February 28th, the next one will be expected on March 31st and not March 28th)
API
🧑💻 Pulse checks can also be created from the API using the type=pulse parameter. Be careful the private pulse endpoint URL is ONLY accessible from the API after creation (or update). Otherwise it's redacted from any GET endpoint for security.
How to send a pulse
Once your check is created (click the save button on the right if not already done), updown will show you a private https URL you can use to send your "pulse" request to:

You can click it to copy the URL to the clipboard. Keep this URL private as anybody querying it (intentionally or not) could skew your monitoring results.
You can then query this URL (using GET, HEAD or POST) in your periodic tasks, at the end of your scripts, etc.. Using the HTTP client of your choice. For example with curl:
> curl -m 10 --retry 5 https://pulse.updown.io/xxxx/YYYYYYYY
OK: ac0607d2-3138-401f-8229-6ca473d03472
Or with powershell.exe on Windows:
> powershell.exe -NoProfile -ExecutionPolicy Bypass -Command "& { [Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12; Invoke-WebRequest -Uri 'https://pulse.updown.io/xxxxxx/yyyyyy' -UseBasicParsing -TimeoutSec 10 }"
That's it 🎉 updown will record this call, mark the check as UP and then wait for your configured duration (e.g. 25 hours in the above example).
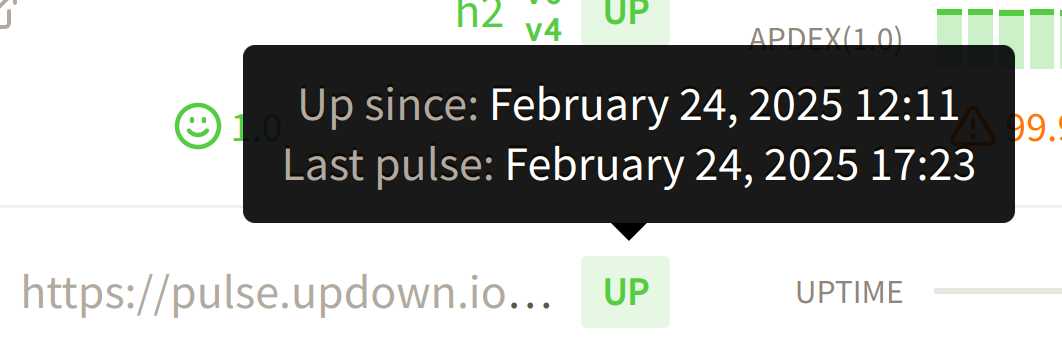
You can check the current state of your check and the time of the last received pulse in the status badge:
The body returned by updown when successful (OK: ac0607d2-3138-401f-8229-6ca473d03472) contains a request ID which you can optionally store or log. It could be useful in case you need to contact us to investigate some issues with your pulse check, providing the request ID will help us locate the query in logs more quickly.
If you prefer to hide this body and get a silent curl call, you can add -sSo /dev/null parameters (--silent, --show-error, and --output)
Reliability
A few words about the reliability: the pulse endpoint (pulse.updown.io) is backed by at least 2 servers at the DNS level:
> host pulse.updown.io
pulse.updown.io has address 178.63.21.176
pulse.updown.io has address 91.121.222.175
pulse.updown.io has IPv6 address 2001:41d0:2:85af::1
pulse.updown.io has IPv6 address 2a01:4f8:141:441a::2
(as of 2025-02-25)
So if the first server is unreachable at the time of the request, your HTTP client should in theory be able to fall back to the other IPs automatically. This is not true for every HTTP client by default unfortunately, but it is true for recent versions of curl at least.
We also recommend a few (optional) parameters for the following reasons:
-m 10is the --max-time parameter and limits the time curl will wait to 10 sec per attempts, so the pulse do not block your scripts for too long in case of timeouts. If you know your network may be slow or congested you may increase this value as needed.--retry 5allows curl to retry the requests when it receives a transient HTTP error code (408, 429, 500, 502, 503 or 504). This way if updown server is responding but temporarily unable to process the request or reach the database, it gives a couple more attempts before giving up. This should be very rare but better be prepared than receiving a false positive alert.
Here is an example using the puuulse.updown.io domain which is intentionally containing one invalid IP (timing out) and one valid IP:
> curl -m 10 --retry 5 -4kv https://puuulse.updown.io/xxxx/YYYYYYYY
* Host puuulse.updown.io:443 was resolved.
* IPv6: (none)
* IPv4: 192.0.2.0, 91.121.222.175
* Trying 192.0.2.0:443...
* ipv4 connect timeout after 5000ms, move on!
* Trying 91.121.222.175:443...
* Connected to puuulse.updown.io (91.121.222.175) port 443
[...]
OK: ac25d296-3208-497a-8781-9bc2cfab461d
Here we gave curl 10 seconds, it first tried the invalid IP and moved on to the second (valid) IP after waiting 5 seconds.
For this testing, we also need to use:
- the
-koption to ignore certificate validity (as the test domainpuuulse.updown.iois not included in the TLS certificate) - the
-voption to see the verbose output with the successive connection attempts. - the
-4option is here to limit the testing to IPv4 for simplicity (and also because curl tends to always pick the good IPv6 first for some reason).
The --retry option is not relevant in this example as we don't have a transient HTTP response code.
Feel free to use this domain to test your own HTTP client if you want to make sure they supports this fallback.
Optionally, you can add the -f (--fail) option to tell curl to exit with a non-zero status (22 actually) instead of showing the response body if the request receives a 4xx or 5xx response. This is useful if you need the non-zero status to detect the failure.
Request body
You can optionally send a body with your request (use a POST request in that case). The body will be stored and can be displayed when you investigate downtimes.
This is extra debugging info that could be helpful for you. For example you can send the duration of your task in here, the machine it was executed on, etc.. In your downtime & recovery alerts you'll find the list of the last pulses and you'll be able to see the body by clicking on them.
Since April 2026You can also specify a string to match in the pulse body (in the "contains" field or via the string_match API parameter). When configured, updown will check the body of each received pulse for that string (case-insensitive). If the string is not found (or no body was sent), the check will be considered DOWN, just like a missing pulse would. For example you could have your cron job send its output as the body, and configure the string match to look for "successfully". This way in addition to detecting missing pulses, you also get alerts for controlled failure cases — and can check the body for details.
Examples in other languages
Ruby
require 'net/https'
# Simple example
Net::HTTP.get(URI('https://pulse.updown.io/xxxx/YYYYYYYY'))
# More complete with custom timeouts and proper IP failover (not implemented by Net::HTTP)
# you can remove the puts or replace them with logging
def updown_pulse! url
uri = URI(url)
ips = Resolv.getaddresses(uri.host) # or e.g. "puuulse.updown.io" for failover testing
raise Resolv::ResolvError.new("no address for #{url.host}") if ips.empty?
begin
Net::HTTP.start(uri.host, 443, ipaddr: ips.shift.to_s, use_ssl: true, open_timeout: 5, read_timeout: 10) do |http|
puts http.get(uri.request_uri).body
end
rescue SystemCallError, Timeout::Error, OpenSSL::SSL::SSLError => err
ips.empty? ? raise : puts(err); retry
end
end
updown_pulse! "https://pulse.updown.io/xxxx/YYYYYYYY"
🪙 Pricing
The pricing for pulse checks will be slightly more complex to estimate but still very fair and cheap:
- Each pulse request will cost 1 credit
- Each missed pulse (configured interval) will also cost 1 credit
So basically if you have a daily cron pulse configured with a notification interval of 25h:
- When the task is running fine, you'll drain 1 credit per day, when the pulse endpoint is called
- And during downtime (no pulse), you'll drain 1 credit every 25h, as updown will check status and sometimes send notifications
That's at most 365 credits / year for this daily pulse example, or about 0.009€ / year maximum ! (even less if you buy credits in larger packs)
For a more expensive pulse check expected every 1 minute, it would be ~1.10€ / month maximum (see pricing table)
So very similar to regular checks in the end, it's the pulse interval which will dictate the pricing and for low frequency tasks it'll be very, very cheap, as you can see above.
⚠️ Important notes
- If you configure a time interval of 25 hours but actually call the pulse endpoint every hour, then obviously you'll use one credit every hour. In addition, the updown credits forecast may be off because it's calculated based on the configured time interval. Finally you'll get alerted quite late (25h after the last pulse) so that's not something we would recommend anyway but just so you know.
- If you disable a pulse check but keep sending the pulse requests, they'll still be processed, recorded and still cost you credits. Because processing those requests will costs us no matter if your check is enabled or disabled. Also this way we can return a 200OK that won't break your scripts and you won't loose any data when you enable the check again.
- If you delete a pulse check but keep sending the pulse requests, they'll return a 404 error and will not cost you credits. But they will be considered abusive (you're supposed to remove the call when you delete the check). So if you keep a lot of them for a some time, we may have to block your IPs and/or account (the same is true for any kind of abusive behavior on the updown.io service in general)
