Blog MongoDB SSD incident postmortem
Note: This article was initially published on Medium in 2019 and later moved to this official updown.io blog.
All times will be given in UTC+2 (CEST) to match monitoring tools screenshots.
April 3rd 2019 at 2:30 am: updown.io primary database (MongoDB) server starts to answer queries about 200 times slower than usual, causing an almost total outage of the website and the monitoring daemons 🔥
Unfortunately MongoDB automatic fail-over mechanism didn't detect this issue because the heartbeat check was still responding quickly, so even though there was a secondary server ready to takeover, it wasn't elected primary automatically. MongoDB ticket: https://jira.mongodb.org/browse/SERVER-29980
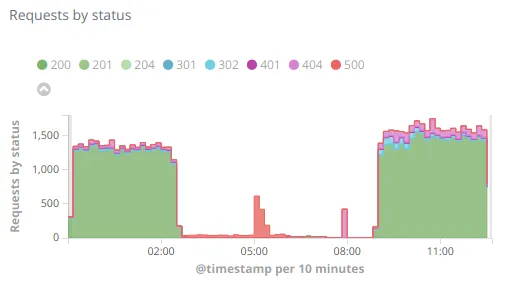
April 3rd 2019 at 8:45 am: Unfortunately I was asleep at that time and only noticed the problem at 8:45. I quickly investigated the primary server and noticed the IO performance issue, after making sure the secondary was ready to takeover I forced the step down of the Primary, which made the whole platform (web and daemons) recover at 8:56 am 🚒 (although with lesser performance because the secondary server is not as powerful)

atop output showing the IO usage (“busy”) and average latency (“avgio”) of the 3 disks
After that I investigated the IO issue and noticed it was caused by one of the SSD (3 total in RAID5), taking this disk out of the array recovered the machine to it’s initial performance level. I created a ticket with my hosting provider to schedule the SSD replacement.
April 4th 2019 at 3:56 am: The night after, the Secondary server fell at 03:56, causing another global outage. This time the issue came from the daily clamscan run (antivirus)+ MongoDB ending up taking all the memory and triggering the kernel's Out Of Memory Killer which killed… MongoDB 🤯🔫
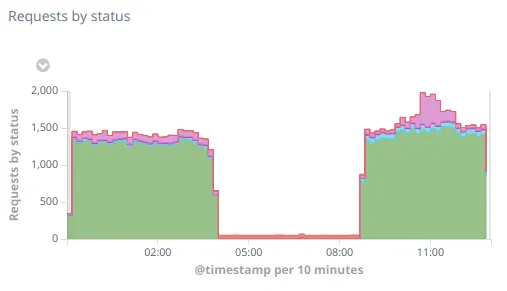
April 4th 2019 at 8:40 am: Again I was asleep and only noticed this at 8:40 where I quickly restarted MongoDB and added some swap space to the machine to try to avoid the issue. At that point I didn't have the time to investigate the cause (clamscan run, as stated above).
April 5th 2019 at 3:56 am: The night after there was a partial outage between 3:56 and 5:30 caused by the clamscan run slowing down the mongo server (because it was taking memory away from mongo). This time the monitoring daemons were not impacted, and the website was (just) slower, but users may also have experienced some connection errors due to the DNS automatic fail-over detecting this server as down and switching to another (the primary, which was currently disabled)
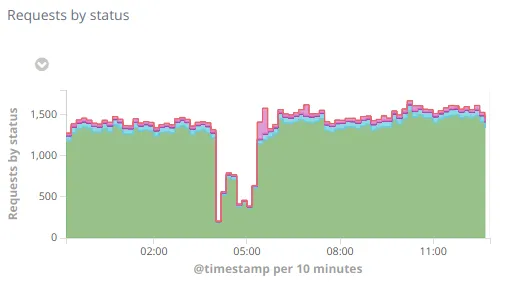
April 5th 2019 at 8:40 am: When I noticed this I disabled the clamscan run and the DNS failover to make sure the secondary has all the ressources it needs. This allowed it to hold up during the following night without trouble 🎉
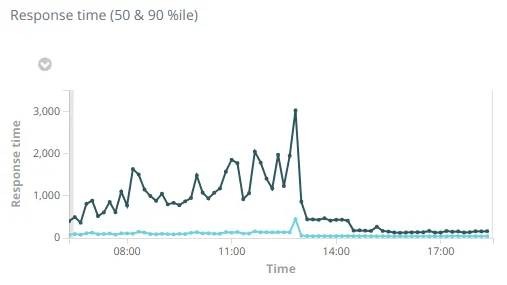
April 6th 2019 at 12:48 pm: Saturday morning I finally had more time to work on this and replaced the secondary server with a more powerful one. It was switched at 12:48 and and since then the response time went back to normal levels:
I got a response from my hosting provider regarding the SSD replacement asking for a couple confirmations but there is no intervention scheduled at this point.
I also started working on a script to detect when MongoDB is up but not responsive to force the step down automatically as it looks like the MongoDB team is not going to address this anytime soon.
April 7th 2019 at 11:47 pm: Sunday morning a funny thing happened: the hosting provider replaced the SSD the last night (Saturday), in the morning I went to add it back to the RAID (which worked smoothly) but noticed that another SSD just died in the same way during the night 😒 I double checked to be sure it wasn't a mistake (replacing wrong disk or swapping) but it wasn't. So I had to take it out of the RAID (after the new one was synced) and asked them to replace this second disk… It looks like they were both way past their rated endurance.
April 16th 2019: Second SSD replaced and added back to the RAID array, the main server looks in better shape now but I'm keeping it secondary for now.
April 22th 2019: After a period of observation, the main server has been switched back to primary (for mongo and web).
Done
✅ Shut down and delete the old secondary once I'm sure I have nothing else to investigate on it.
✅ Make sure the new secondary server can withstand being primary for a several days (the previous one had not been tested during a night with clamscan for example).
✅ Test the automatic step down script one the primary server is back on track.
✅ Finally provide a proper status page for updown.io. I started one → https://status.updown.io/ it's not perfect and all automated yet but it'll come ☺
November 6th 2019: Fun update 🥳, 7 months later the third SSD in the server died, in the middle of the night of course. But fortunately thanks to the automatic detection script I wrote, the MongoDB primary was automatically stopped, allowing the fallback to secondary and thus reduced the downtime to under 10 minutes! 🎉 Not perfect but much better than before.
May 23rd 2020: And another 6 months later, I was able to finally remove this manual script after MongoDB "opened" the Storage Node Watchdog down to the community edition (before that it was only available in the enterprise edition 💰). After enabling it and testing it for a while it was a success so I deleted the custom script 🎉 Yay!

Comments
Sign in to comment